
#191 Mechanize
- Download:
- source code
- mp4
- m4v
- webm
- ogv
上一集我们使用Nokogiri抓取单个HTML页面的内容. 如果有更复杂的抓取需求,像需要先登陆才能抓取数据的,这种简单的方法就行不通了,所以这次我们使用Mechanize来交互网站,抓取数据.
我们将要使用的网站是Ta-da list. 它是37 Signals的一个to_do list应用. 我们已经注册了一个帐号,并创建了一个清单列表. 如果想再次查看这个列表,就必须先登陆这个站点,然后点击页面上的清单名称.
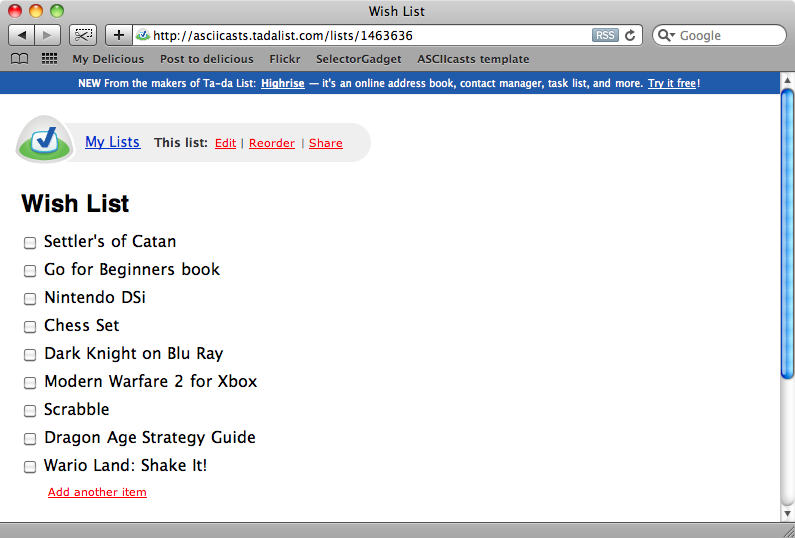
现在需要将清单内容自动导入到rails应用的商品列表. 因此我们需要交互这个Ta-da List,得到这些商品,然后就可以用上一集写的脚本来来获取每个商品价格.
由于清单页面是私人的,我们不能访问列它的URL. 使用curl 请求页面,会看到下面的内容.
<p>所以我们不能直接访问清单页面. 访问前必须要先登陆应用. 这时候就需要用到Mechanize了. Mechanize使用Nokogiri,并扩展了一些其他的功能来交互网站,可以像点击链接,提交表单一样用来处理一些任务.</p> <p>Mechanize跟一般的gem一样安装:</p> ``` terminal sudo gem install mechanize
安装完成后,可以打开一个Rails console看看它是怎么工作的. 首先,需要引用Mechanize.
``` terminal >> require 'mechanize' => []
<p>接下来,需要实例化一个Mechanize agent:</p>
``` terminal
> agent = WWW::Mechanize.new
=> #<WWW::Mechanize:0x101c74780 @follow_meta_refresh=false, @proxy_addr=nil, @digest=nil, @watch_for_set=nil, @html_parser=Nokogiri::HTML, @pre_connect_hook=#<WWW::Mechanize::Chain::PreConnectHook:0x101c74190 @hooks=[]>, @open_timeout=nil, @log=nil, @keep_alive_time=300, @proxy_pass=nil, @redirect_ok=true, @post_connect_hook=#<WWW::Mechanize::Chain::PostConnectHook:0x101c74168 @hooks=[]>, @conditional_requests=true, @password=nil, @cert=nil, @user_agent="WWW-Mechanize/0.9.3 (http://rubyforge.org/projects/mechanize/)", @pluggable_parser=#<WWW::Mechanize::PluggableParser:0x101c74550 @default=WWW::Mechanize::File, @parsers={"application/xhtml+xml"=>WWW::Mechanize::Page, "text/html"=>WWW::Mechanize::Page, "application/vnd.wap.xhtml+xml"=>WWW::Mechanize::Page}>, @verify_callback=nil, @connection_cache={}, @proxy_user=nil, @pass=nil, @ca_file=nil, @request_headers={}, @user=nil, @cookie_jar=#<WWW::Mechanize::CookieJar:0x101c746b8 @jar={}>, @scheme_handlers={"https"=>#<Proc:0x00000001020c12c0@/Library/Ruby/Gems/1.8/gems/mechanize-0.9.3/lib/www/mechanize.rb:152>, "file"=>#<Proc:0x00000001020c12c0@/Library/Ruby/Gems/1.8/gems/mechanize-0.9.3/lib/www/mechanize.rb:152>, "http"=>#<Proc:0x00000001020c12c0@/Library/Ruby/Gems/1.8/gems/mechanize-0.9.3/lib/www/mechanize.rb:152>, "relative"=>#<Proc:0x00000001020c12c0@/Library/Ruby/Gems/1.8/gems/mechanize-0.9.3/lib/www/mechanize.rb:152>}, @redirection_limit=20, @proxy_port=nil, @history_added=nil, @auth_hash={}, @read_timeout=nil, @keep_alive=true, @history=[], @key=nil>使用agent我们就可以登陆Ta-da list . 要解决这个,我们需要获取登陆页面,输入密码然后提交表单.
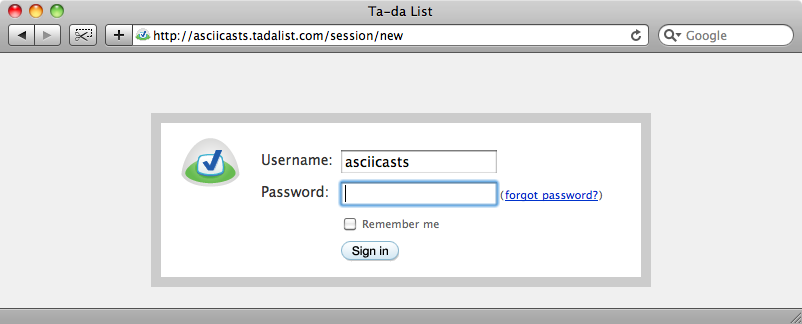
通过调用agent.get,并传入页面的URL, 发送一个GET请求来获取页面内容
``` terminal >> agent.get("http://asciicasts.tadalist.com/session/new") => #
<p>这里返回的是一个<code>Mechanize::Page</code>对象,它包含这个页面里所有元素内容. 对于我们这里的页面,需要的是登陆表单.</p>
<p>任何时候调用<code>agent.page</code>都会返回当前page对象,可以通过调用页面属性来访问页面上的不同元素. 例如,要得到页面上的表单元素,可以调用<code>agent.page.forms</code>,它返回的是一个<code>Mechanize::Form</code>对象数组. 由于这个页面只有一个表单,所以调用<code>agent.page.forms.first</code>就可以索引到我们需要的登陆表单. 后面要用到这个表单,所以先将该表单标记为一个变量.</p>
``` terminal
>
> form = agent.page.forms.first
=> #<WWW::Mechanize::Form
{name nil}
{method "POST"}
{action "/session"}
{fields
#<WWW::Mechanize::Form::Field:0x1035f1708
@name="username",
@value="asciicasts">
#<WWW::Mechanize::Form::Field:0x1035ef4a8 @name="password", @value="">}
{radiobuttons}
{checkboxes
#<WWW::Mechanize::Form::CheckBox:0x1035eeb48
@checked=false,
@name="save_login",
@value="1">}
{file_uploads}
{buttons}>通过上面输出form的fields集合,我们发现用户名已经被填写,密码却为空. 在这里可以通过为Ruby对象设置属性来完成表单的填写.下面是设置密码:
<p>提交这个表单是相当简单, 唯一需要做的是调用<code>form.submit</code>. 它将返回另外一个<code>Mechanize::Page</code>对象.</p>
``` terminal
>> form.submit
=> #<WWW::Mechanize::Page
{url #<URI::HTTP:0x10336ad68 URL:http://asciicasts.tadalist.com/lists>}
{meta}
{title "My Ta-da Lists"}
{iframes}
{frames}
{links
#<WWW::Mechanize::Page::Link "Highrise" "http://www.highrisehq.com">
#<WWW::Mechanize::Page::Link "Try it free" "http://www.highrisehq.com">
#<WWW::Mechanize::Page::Link
"Tada-mark-bg"
"http://asciicasts.tadalist.com/lists">
#<WWW::Mechanize::Page::Link "Create a new list" "/lists/new">
#<WWW::Mechanize::Page::Link "Wish List" "/lists/1463636">
#<WWW::Mechanize::Page::Link
"Rss"
"http://asciicasts.tadalist.com/lists.rss?token=8ee4a563af677d3ebf3ceb618dac600a">
#<WWW::Mechanize::Page::Link "Log out" "/session">
#<WWW::Mechanize::Page::Link "change password" "/account/change_password">
#<WWW::Mechanize::Page::Link "change email" "/account/change_email_address">
#<WWW::Mechanize::Page::Link "cancel account" "/account/destroy">
#<WWW::Mechanize::Page::Link "FAQs" "http://www.tadalist.com/help">
#<WWW::Mechanize::Page::Link
"Terms of Service"
"http://www.tadalist.com/terms">
#<WWW::Mechanize::Page::Link
"Privacy Policy"
"http://www.tadalist.com/privacy">
#<WWW::Mechanize::Page::Link
"other products from 37signals"
"http://www.37signals.com">}
{forms}>上面就是这个页面的内容,显示了我们的清单,接下来需要做的就是点击链接去到商品列表页面. 下面是浏览器中的对应页面. 当使用Mechanize时,它可以帮助我们模拟浏览器以便你决定下一步执行什么脚本.
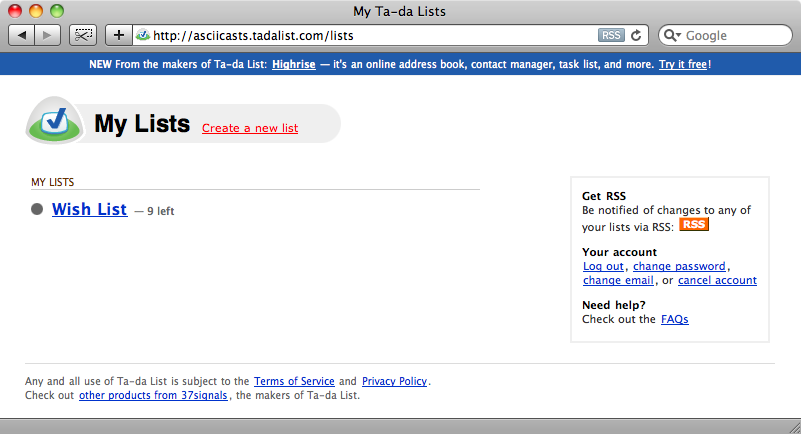
要获取清单列表,我们需要点击"Wish List"链接. 但是页面上有很多链接,怎样找到Mechanize要点击的链接呢? 可以通过agent.page.links获得页面的所有链接,然后进行迭代,循环每个链接的text属性,找到我们需要的.另外有一个更容易的办法就是通过 link_with:
<p>使用<code>link_with</code>方法可以返回一个匹配指定条件的链接,这样就可以获取带有"Wish List"文本的链接. 表单也有类似的方法<code>form_with</code>. 还有匹配多个对象的方法 ,<code>links_with</code> 和<code>forms_with</code>是用来匹配指定条件的多个链接或多个表单.</p>
<p>既然已经找到了需要的链接,我们就可以点击它,它会定向到清单列表页面.</p>
``` terminal
agent.page.link_with(:text => "Wish List").click
=> #<WWW::Mechanize::Page
{url
#<URI::HTTP:0x103261138 URL:http://asciicasts.tadalist.com/lists/1463636>}准备工作已经完成,我们已经找到了想要抓取内容的页面. 现在可以使用Nokogiri来提取内容了.但是首先还需要获得匹配列表项的CSS选择器 跟上次一样,我们需要用SelectorGadget来获取对应的选择器.
点击清单的第一项,会选中第一个item,当点击下一个时,所有的清单项都被选中了,于是找到了需要的选择器.edit_item.
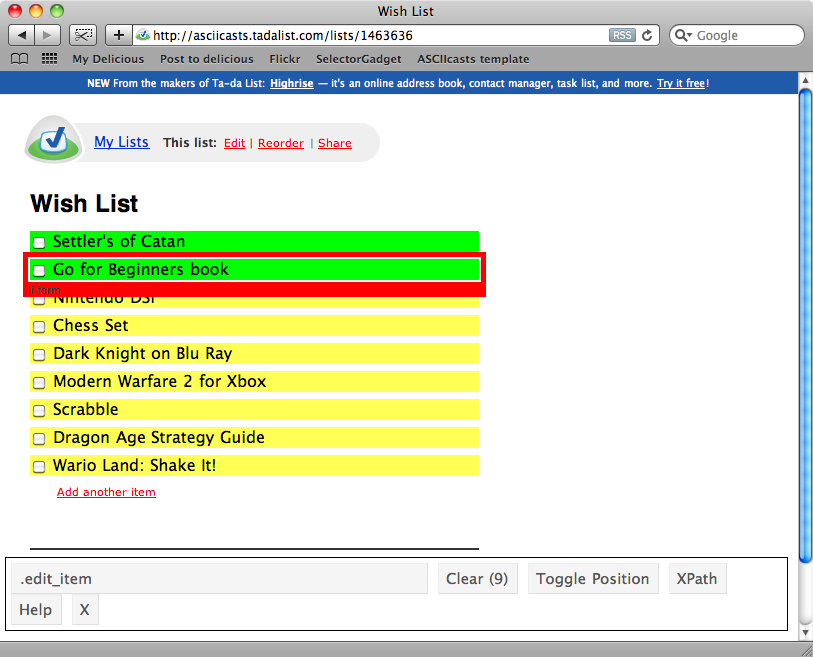
使用Nokogiri,可以调用page对象的两个方法来提取页面元素.第一个是at,它返回匹配对应选择器的一个元素.
<p>第二个是<code>search</code>. 类似地,它返回匹配到的所有元素的数组.</p>
``` ruby
agent.page.search(".edit_item")在列表中有一些items,因此需要使用第二个方法. 使用上面的命令将返回一个Nokogiri::XML::Element对象数组,每一个元素代表清单中的一个列表项.我们可以通过控制输出来让结果具有可读性.
``` terminal >> agent.page.search(".edit_item").map(&:text).map(&:strip) => ["Settler's of Catan", "Go for Beginners book", "Nintendo DSi", "Chess Set", "Dark Knight on Blu Ray", "Modern Warfare 2 for Xbox", "Scrabble", "Dragon Age Strategy Guide", "Wario Land: Shake It!"]
<p>获取每个元素的<code>text</code>属性,并调用strip方法来去掉空白部分.就可以获得这些列表项名字的数组,这刚好是我们需要的.</p>
<h3>集成Mechanize到Rails应用</h3>
<p>知道了如何使用Mechanize,现在就可以将刚才的代码集成到Rails应用里. 我们将使用上集使用过的shop应用.</p>
<div class="imageWrapper">
<img src="http://railscasts.com/static/episodes/asciicasts/E191I05.png" width="808" height="371" alt="Our application's product list."/>
</div>
<p>跟抓取价格相反,这次我们需要从Ta-da list导入我们的新商品.可以在<code>/lib/tasks/product_prices.rake</code>里创建一个rake任务来处理这个.但是我们该怎么写代码呢?接下来从console开始,然后复制里面的代码.</p>
<p>但是从console里面复制代码是有些困难,因为它是每一行复合输出的. 可以用下面的命令来返回我们之前的所有输入.</p>
``` terminal
>> puts Readline::HISTORY.entries.split("exit").last[0..-2].join("\n")
require 'mechanize'
agent = WWW::Mechanize.new
agent.get("http://asciicasts.tadalist.com/session/new")
form = agent.page.forms.first
form.password = "password"
form.submit
agent.page.link_with(:text => "Wish List").click
agent.page.search(".edit_item").map(&:text).map(&:strip)
=> nil上面已经列出了需要复制到rake里面的代码. 现在我们清理一下代码,然后去循环提取到的商品,为每一个创建一个Product.
<p>当然,可以去掉用户名和密码,通过控制参数传入它们. 现在我们需要切换窗口,看看我们的rake任务能不能正常工作.</p>
``` terminal
$ rake import_list
(in /Users/eifion/rails/apps_for_asciicasts/ep191/shop)如果运行脚步后,没有异常,就可以刷新products页面了.
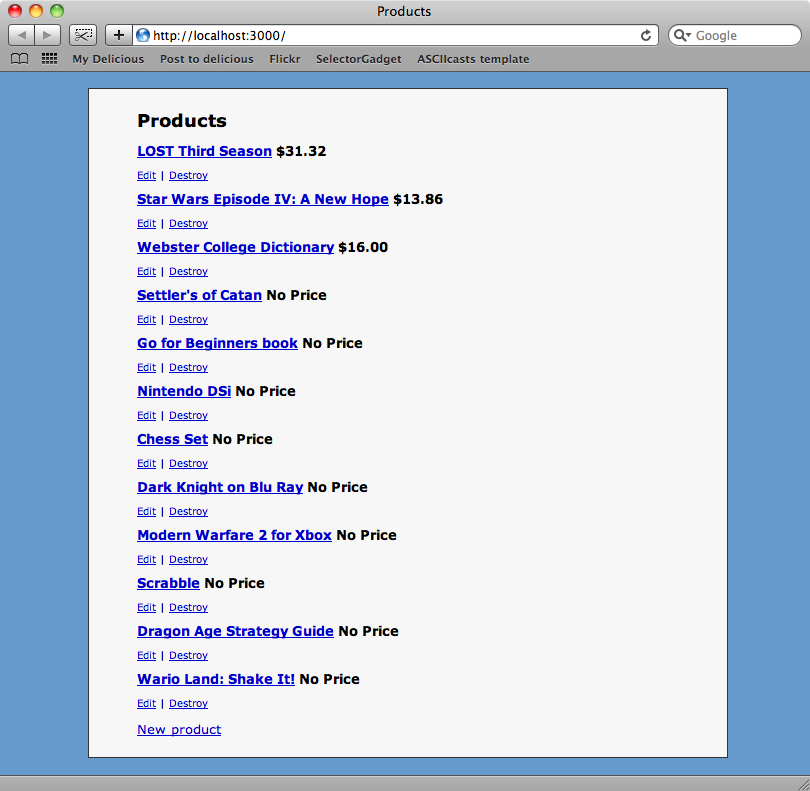
脚步已经工作了: 现在已经为列表中的每一个商品创建了一个Product. 如果我们运行上集中的rake任务,我们就可以获得所有新商品的价格.
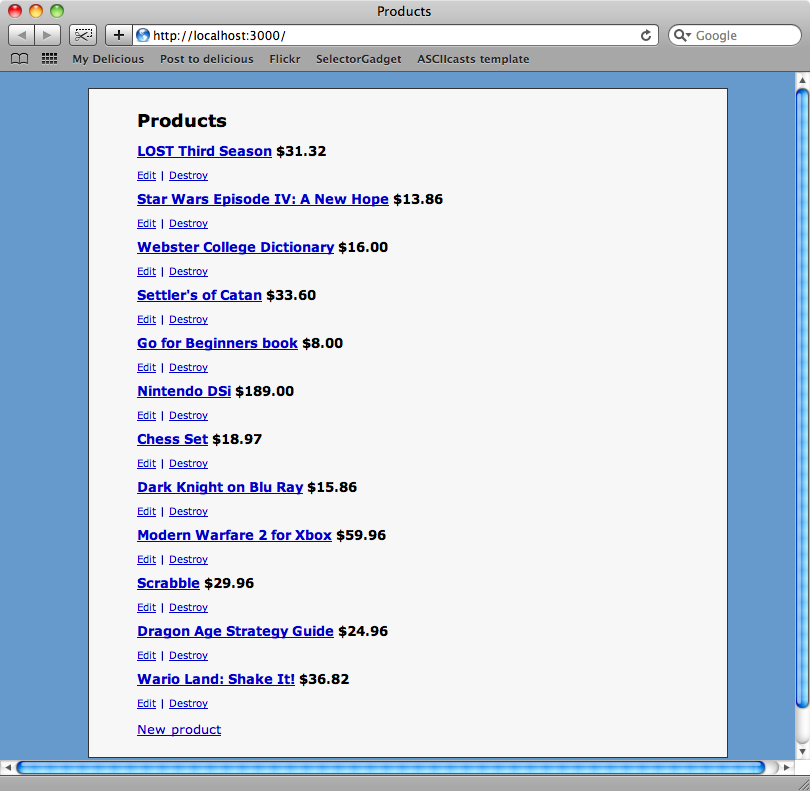
到目前为止,所有的工作都已经完成了. 我们已经通过Mechanize和Nokogiri来在页面间导航,填写表单进行页面交互,点击超链接获取我们想要的信息. 对于网站的数据抓取工作,这是一个非常不错的解决办法.
