
#115 Model Caching (revised)
- Download:
- source code
- mp4
- m4v
- webm
- ogv
Below is a screenshot from a page that shows a number of articles, each of which has a number of comments.
We want to improve the performance of this application by using caching. To do this we’d generally first consider fragment caching, which we showed in episode 90, but sometimes caching at the view layer isn’t an option, especially if a page is very dynamic and changes for each different user. In these cases we can add caching at a lower level which allows us to bypass the database while keeping our views nice and flexible and it’s this that we’ll be covering in this episode.
Before we try to optimize our application it’s a good idea to profile it to work out where the bottlenecks are. We already have MiniProfiler set up, like we showed in episode 368 and if we use this to examine the page that displays a single article we’ll see that it makes four database queries, although as our application is simple it doesn’t spend much time in the database at all, less that 2% of the total time.
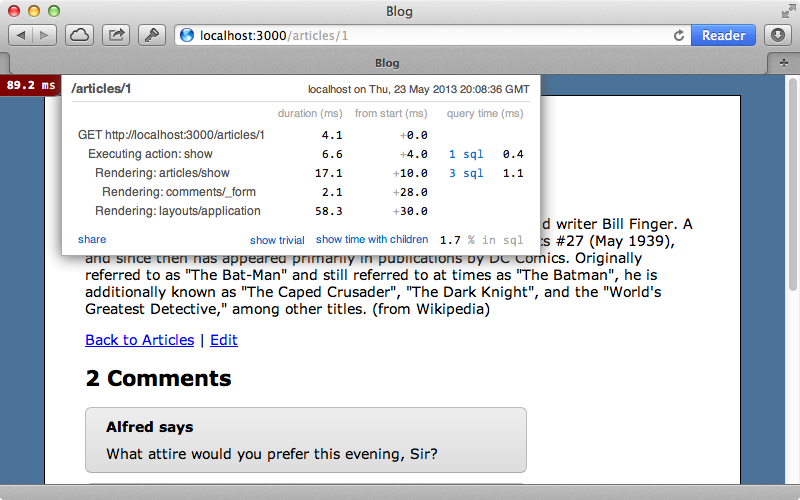
In more complex applications this number is likely to be much higher and will give you a good idea as to how much benefit there is to be gained from caching at a lower level. What we’ll demonstrate in this episode won’t benefit our application much, but it will serve as an example of how we can reduce the database access through low-level caching.
How Rails Handles Caching
Rails makes it easy to cache things at a low level with the Rails.cache object. This works like a key-value store system and we write to it by supplying a key and a value and read values back using the key.
>> Rails.cache.write('date', Date.today) => true >> Rails.cache.read('date') => Thu, 23 May 2013
We can also use a fetch method which attempts to read a value from the cache and triggers a block if that value doesn’t exist, writing the result to the cache against the supplied key. When we call this again it reads the value from the cache.
>> Rails.cache.fetch('time') { Time.now } => 2013-05-23 21:22:56 +0100 >> Rails.cache.fetch('time') { Time.now } => 2013-05-23 21:22:56 +0100
By default the cache is stored in the file system which can be a little slow. To speed things up we can switch to a memory-based store and in production it’s a good idea to use Memcached which we can do by uncommenting a line in the config file. In a Rails 4 application this will use the Dalli gem which was covered in episode 380.
# Use a different cache store in production config.cache_store = :mem_cache_store
Caching Computed Properties
Let’s see how we can use this cache store to avoid hitting the database. First we’ll use it to cache computed properties on a model. ActiveRecord provides a cache_key method which is handy for auto-expiring caches. This includes the model’s name, id and updated_at timestamp so if we update the article in any way this key will change.
>> article = Article.first Article Load (0.6ms) SELECT "articles".* FROM "articles" LIMIT 1 => #<Article id: 1, name: "Batman", published_at: "2013-05-21 19:38:29", author_id: 1, content: "Batman is a fictional character created by the arti...", created_at: "2013-05-23 19:38:29", updated_at: "2013-05-23 19:38:29"> >> article.cache_key => "articles/1-20130523193829" => "articles/1-20130523193829" >> article.touch SQL (2.2ms) UPDATE "articles" SET "updated_at" = '2013-05-24 19:31:53.989350' WHERE "articles"."id" = 1 => true >> article.cache_key => "articles/1-20130524193153"
If pass a model object to fetch it will automatically use its cache_key and we can supply multiple keys in an array, which are joined together. If we have a property that we want to compute on a model we can execute some code within a block and this will be triggered when the key is set. The next time we run this code the block won’t be executed again unless the article has changed causing the key to change.
>> Rails.cache.fetch([article, "foo"]) { 123 }
We’ll use this now in our app. The computed property we want to cache is the number of comments for each article. We currently perform an SQL query to get this but if we cache this value we can avoid this. The view code that displays the comment count looks like this:
<h2><%= pluralize(@article.comments.size, "Comment") %></h2>
Instead of calling comments.size on the article we’ll use a new method called cached_comments_count.
<h2><%= pluralize(@article.cached_comments_count, "Comment") %></h2>
In this method we want to get the number of comments that the article has then cache that value.
def cached_comments_count Rails.cache.fetch([self, "comments_count"]) { comments.size } end
Here we try to fetch a cached value based on the article’s cache_key and the name “comments_count” and set it to the number of comments that the article has. As before the value in the block is only executed the first time or when the article is updated. The number of comments is fairly independent of the article’s properties so if we add or remove comments to an article we’ll end up with a stale cache as the key won’t change. We can resolve this by modifying the Comment model so that it touches the related article when a comment is updated.
class Comment < ActiveRecord::Base belongs_to :article, touch: true attr_accessible :name, :content end
Now the article’s cache is expired whenever one of its comments is updated or deleted or when a new comment is created for it. If we reload the page for an article a couple of times a new cache is created to store the number of comments which means that the number of SQL queries the page makes is reduced from four to three. When we write a new comment for the article the cache is expired as the article is touched. We could use a counter cache column for this but this would mean that we have to alter the database schema and our approach is more flexible as we can use to cache any property that we want to, even full-on model associations. To demonstrate this we’ll cache all of the articles’ comments. These are rendered out in the view, but instead of fetching them directly from the article we’ll call a new cached_comments method.
<div id="comments"> <%= render @article.cached_comments %> </div>
It’s generally a good idea to write a separate method to fetch cached objects instead of overwriting existing methods as this gives us more control over when we use the cached version. We’ll write the cached_comments method in the Article model.
def cached_comments Rails.cache.fetch([self, "comments"]) { comments.to_a } end
This method is similar to cached_comments_count and it returns an array of comments. We convert the comments to an array so that we’re not working with a relation object and this makes it clear that we can’t call additional queries on it.
When we reload the page a couple of times now we can see from MiniProfiler that the page now only makes two database queries. If we add another comment to a page the cache for the article’s comments will expire along with the article they’re associated with. We need to be careful when we store ActiveRecord model objects directly in the cache like this as these will be marshalled and then unmarshalled. If the database schema changes this can cause unintended side effects. In these cases when whenever we change the database schema for an ActiveRecord model we should flush the relevant caches as well.
Caching Model Objects
Our article page now only makes two database queries; let’s see what we can do to remove them. The first one fetches an article by its id while the second fetches an author by its id and these are a little tricky to cache but we can try. We fetch the article in the ArticlesController’s show action which makes a database query. Instead of calling find to get the article we’ll use a new cached_find method.
def show @article = Article.cached_find(params[:id]) @comment = Comment.new end
This new method will fetch the article then cache it. To uniquely identify it in the cache we’ll use the article’s name and id.
def self.cached_find(id) Rails.cache.fetch([name, id]) { find(id) } end
Unfortunately this cache won’t auto-expire so if we change the properties of an article we’ll end up with a stale cache, but the name and id won’t change to give us a different key. This means that we’ll need to expire the cache in another way. If we’re using Memcached we can use the expires_in option to expire the cache every few minutes but this means that we could still be working with data that’s out of date so there are disadvantages to this approach. Alternatively we can listen for a callback hook that fires when an article is updated or deleted and delete the relevant item from the cache then.
after_commit :flush_cache def flush_cache Rails.cache.delete([self.class.name, id]) end
With this change in place our page now only makes one database query and if we update an article its cache is expired and the changes made shown on the page.
We’re down to our final database query now and this fetches the author that the article is associated with. If we just want to display the author’s name on the page we could cache this value directly, but let’s say that we want to display other information about the author on the page. We’ll cache the Author record in a similar way to what we’ve done before. In the view we’ll call a cached_author method to fetch the author.
<p class="info"> Published on <%= @article.published_at.strftime("%B %e, %Y") %> by <%= @article.cached_author.name %> </p>
We’ll need to write this method in the model class. We could treat the author as a property on our article like we do with the comments but this means that whenever we change an author we have to touch all the associated articles which could be many. Instead we’ll cache the authors separately using a similar technique to that we used when we found articles by their id.
class Author < ActiveRecord::Base has_many :articles attr_accessible :name after_commit :flush_cache def self.cached_find(id) Rails.cache.fetch([name, id], expires_in: 5.minutes) { find(id) } end def flush_cache Rails.cache.delete([self.class.name, id]) end end
In the Article model we can now use this to fetch the cached author.
def cached_author Author.cached_find(author_id) end
When we reload the page now it makes no database queries at all.
Using Cached Items on Different Pages
What’s good about caching at a low level like this is that it’s easy to apply anywhere in our application. For example in the articles list page a number of queries are performed and we can reduce this significantly by making use of the same caching.
<h1>Articles</h1> <div id="articles"> <% @articles.each do |article| %> <h2><%= link_to article.name, article %></h2> <p class="info"> Published on <%= article.published_at.strftime("%B %e, %Y") %> by <%= article.cached_author.name %> </p> <%= simple_format article.content %> <p><%= link_to pluralize(article.cached_comments_count, "comment"), article %></p> <% end %> </div> <p><%= link_to "New Article", new_article_path %></p>
Here we’ve changed the code that renders each article’s author to use cached_author and similarly used cached_comments_count to get the number of comments for each article. This reduces the number of database queries that the page makes down to one. The one remaining query fetches all the articles that have been published: in our ArticlesController’s index action we call Article.published to fetch the articles. As before we’ll write a cached version of this method in the model.
def self.cached_published Rails.cache.fetch([name, "published"]) do published.to_a end end
The tricky part is expiring the cache. Any articles that change make the cache stale. The easiest solution is to flush the cache whenever an article is updated or deleted.
def flush_cache Rails.cache.delete([self.class.name, id]) Rails.cache.delete([self.class.name, "published"]) end
Alternatively we could use an auto-expiring key.
def self.cached_published updated_at = published.maximum(:updated_at) Rails.cache.fetch([name, updated_at]) do published.to_a end end
Now whenever we update an article we can auto-expire the key. This technique still requires a database query to fetch the last-updated article, which should be quick, but this isn’t as efficient as expiring the cache whenever an article is updated. Whichever approach we use we need to take care when a query is based on the current time, like our published scope as this means that the cache may become stale without any articles changing. To get around this we can use the expires_in option to expire our cache occasionally whether an article is updated or not.
def self.cached_published Rails.cache.fetch([name, "published"], expires_in: 5.minutes) do published.to_a end end
Our index page can now be displayed without making any database queries as can the page for a single article. As with any performance optimization we should profile these pages thoroughly before and after optimizing it to make sure that it is making a benefit.
Adding caching from scratch is fairly easy but if you’d rather use a gem take a look at the IdentityCache gem5 which does more than what’s been covered here.
Low-level caching can be used for much more than reducing access to the database. We can also use it to cache the results of an API call or any slow operation.
